The Elements of Statistical Learning (Hastie, Springer, 2016) 파이썬 라이브러리를 활용한 머신러닝 (안드레아스 뮐러 저, 박해선 역, 한빛미디어, 2017)
Improper Preprocessing
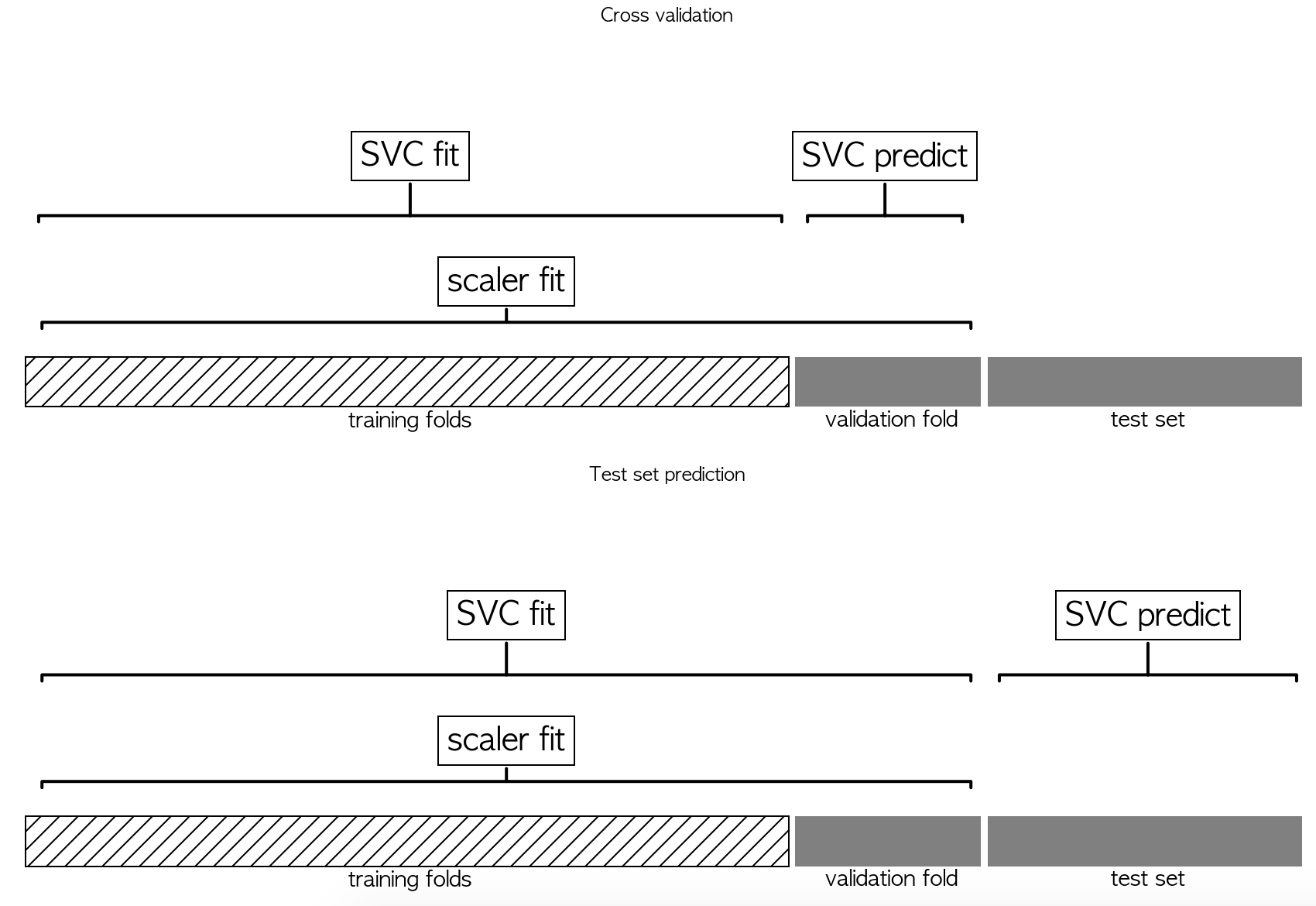
교차 검증에서 검증 폴드 데이터의 정보가 모델 구축 과정에 누설되면 교차 검증에서 낙관적인 결과가 만들어진다. 아래 그림에서는 파라미터 선택을 위해 scaler.fit과 SVC.predict가 모두 검증 폴드를 사용하고 있다. 하지만 모델의 성능을 평가할 때는 scaler.fit이 테스트 세트에 적용되지 않는다. (아래와 같은 문제를 해결하기 위해 Pipeline을 사용한다.)
[Pipeline 사용 예시]
1 | |
교차 검증에서 정보 누설의 영향
무작위로 생성된 X와 y에는 아무런 관계가 없다. (독립)
1 | |
아래와 같이 피처를 선택하고 학습을 시키면 다음과 같은 점수를 얻는다.
1 | |
1 | |
$R^2$가 0.91로 매우 좋은 모델이라고 생각할 수 있지만, 데이터셋을 무작위로 만들었기 때문에 불가능한 일이다. 교차 검증 밖에서 특성을 선택했기 때문에 훈련과 테스트 폴드 양쪽에 연관된 특성이 찾아질 수 있다. 테스트 폴드에서 유출된 정보는 매우 중요한 역할을 하기 때문에 비현실적으로 높은 결과가 나왔다. 이 결과를 Pipeline을 이용한 교차 검증과 비교하면 다음과 같다.
1 | |
1 | |
이번에는 $R^2$가 음수로 성능이 매우 나쁘 모델임을 나타낸다. Pipeline을 사용했기 때문에 특성 선택이 교차 검증 반복 안으로 들어갔다. 즉, 훈련 폴드를 사용해서만 특성이 선택되었고 테스트 폴드는 사용되지 않았다는 뜻이다. 특성 선택 단계에서 타깃값과 연관된 훈련 폴드의 특성을 찾았지만 전체 데이터가 무작위로 만들어졌으므로 테스트 폴드의 타깃과는 연관성이 없다. 이는 특성 선택 단계에서 일어나는 정보 누설을 막는 것이 모델의 성능을 평가하는 데 큰 차이를 만든다는 것을 보여준다.